Next.js 13のSEO対策
静的メタデータ
Next.js 13 では、ファビコンやタイトルなどのメタデータを作成するために、個別のファイルを作成する必要はありません。代わりに、新しいメタデータ API を使用してこれらを作成します。
かなり簡素にかけて、app 直下のlayout.tsxに以下のように記述します。
metadataはpage.tsxに記述することもできますが、CCではなくSCに記述する必要があります。
export const metadata: Metadata = {
title: 'つぼログ',
description: 'React, Next JS, Flutter, Dart, TypeScript, JavaScript などの技術ブログです。',
};ブラウザ画面のタブ部分を確認すると、以下のようになっていることが確認できます。

またページのソースを確認すると、説明も設定されていることが確認できます。

動的メタデータ
静的なページではなく、動的なページでタイトルや説明を動的に作成する方法を説明します。
ここでは例として、ブログ投稿ページのメタデータを動的に作成する方法を説明します。
ブログ投稿ページのメタデータを動的に作成するには、generateMetadata という非同期関数を使用します。この関数は、ページのパラメータを受け取り、メタデータを返します。blog/[slug]/page.tsxに以下を追加します。
interface PageProps {
params: {
slug: string;
};
}
export async function generateMetadata({ params }: PageProps) {
// ブログのデータを取得
const blog = await getDocFromParams(params.slug);
return {
title: blog.title,
description: blog.description,
};
}ブログページにアクセスして、ブラウザのタブ部分を確認すると、以下のようにブログのタイトルが設定されていることが確認できます。
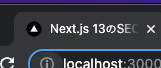
また Twitter のようにタイトルの横にサイト名を表示したい場合は、app 直下のlayout.tsxに以下のように記述します。
templateにはシングルクオート('')やダブルクオート("")ではなくバッククオート(``)で囲む必要があります。
export const metadata = {
title: {
default: 'つぼログ',
template: `%s | つぼログ`,
},
description: 'つぼログでは、Next.js, Flutterに関する技術ブログを発信します。',
};また title を以下のように設定することで、一部のページではサイト名を表示しないようにすることもできます。
export const metadata: Metadata = {
title: {
absolute: '下書き',
},
description: '執筆中の記事を一覧で表示します。',
};Canonical URL
Canonical URL は、ページのコンテンツが複数の URL に存在する場合に、検索エンジンに対して正しい URL を伝えるために使用されます。
その前に、Canonical URL が必要なケースを確認します。
例えば、以下のようなページがあるとします。
この場合、ページのコンテンツは異なる URL に存在しますが、コンテンツは同じです。このような場合、検索エンジンはどの URL をインデックスするべきかを判断することができません。
この問題を解決するために、Canonical URL を使用します。重複しますが Canonical URL は、ページのコンテンツが複数の URL に存在する場合に、検索エンジンに対して正しい URL を伝えるために使用されます。
先程のblog/[slug]/page.tsxの metadata に次のようにcanonicalを追加します。
export async function generateMetadata({ params }: PageProps) {
// ブログのデータを取得
const blog = await getDocFromParams(params.slug);
return {
title: blog.title,
description: blog.description,
canonical: `https://tsubolog.vercel.app/blog/${blog.slug}`,
};
}検証モードで head タグを確認すると、以下のようにcanonicalが設定されていることが確認できます。

サイトマップ
サイトマップは、検索エンジンのクローラーがあなたのサイトをより効率的にクロールするのを助けるためのものです。
サイトマップを作成するには、sitemap.tsファイルを作成します。このファイルは、app の直下に作成する必要があります。
export default async function sitemap() {
const baseUrl = 'https://tsubolog.vercel.app';
const blogsUrls =
allBlogs.map((blog) => {
return {
url: `${baseUrl}/blog/${blog.slug}`,
lastModified: new Date(),
};
}) ?? [];
return [
{
url: baseUrl,
lastModified: new Date(),
},
...blogsUrls,
];
}http://localhost:3000/sitemap.xmlを開くと、以下のようにサイトマップが表示されます。
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://tsubolog.vercel.app</loc>
<lastmod>2023-05-24T14:00:00.000Z</lastmod>
</url>
<url>
<loc>https://tsubolog.vercel.app/blog/nextjs-seo</loc>
<lastmod>2023-05-24T14:00:00.000Z</lastmod>
</url>
OG(Open Graph) 画像
OG 画像は、Twitter や Facebook などのソーシャルメディアで、リンクをシェアした際に表示される画像です。
OG 画像を作成するには、opengraph-image.tsxファイルを作成します。
スタイルにTailwind CSSを使用している場合、classNameではなくtwを使用する必要があります。
import { notFound } from 'next/navigation';
import { ImageResponse } from 'next/server';
import { allBlogs } from '@/.contentlayer/generated';
import getReadingTime from '@/lib/getReadingTime';
import { formatDate } from '@/lib/utils';
export const size = {
width: 1200,
height: 630,
};
interface PageProps {
params: {
slug: string;
};
}
export const alt = 'つぼログ | Blog';
export const contentType = 'image/png';
async function getDocFromParams(slug: PageProps['params']['slug']) {
const blogs = allBlogs.find((blog) => blog.slugAsParams === slug);
if (!blogs) notFound();
return blogs;
}
export default async function og({ params }: { params: { slug: string } }) {
const slug = params.slug;
const blog = await getDocFromParams(slug);
return new ImageResponse(
(
<div tw="relative flex w-full h-full flex items-center justify-center">
<div tw="absolute flex inset-0">
<img
tw="flex flex-1"
src={blog.image + '&w=1200&h=630&auto=format&q=75'}
alt={blog.title!!}
style={{ width: '1200px', height: '630px' }}
/>
<div tw="absolute flex inset-0 bg-black bg-opacity-50" />
</div>
<div tw="flex flex-col text-neutral-50">
<div tw="text-7xl font-bold">{blog.title}</div>
<div tw="flex mt-6 flex-wrap items-center text-4xl text-neutral-200">
<div tw={`font-medium text-indigo-600`}>{blog.title}</div>
<div tw="w-4 h-4 mx-6 rounded-full bg-neutral-300 " />
<div tw="w-4 h-4 mx-6 rounded-full bg-neutral-300" />
<div>{getReadingTime(blog.description!!)}</div>
<div tw="w-4 h-4 mx-6 rounded-full bg-neutral-300" />
<div>{formatDate(blog.date)}</div>
</div>
</div>
</div>
),
size,
);
}ロボットの設定
robots.txtファイルを作成することで、検索エンジンのクローラーがあなたのサイトのどの URL にアクセスできるかを指示できます。robots.txtファイルは、ルートセグメントに配置する必要があります。
例えば、以下のような静的な robots.txt ファイルを作成することができます:
User-Agent: *
Allow: /
Disallow: /private/
Sitemap: https://acme.com/sitemap.xmlまた、以下のように robots.ts ファイルを作成して、Robots オブジェクトを返すこともできます:
import { MetadataRoute } from 'next';
export default function robots(): MetadataRoute.Robots {
return {
rules: {
userAgent: '*',
allow: '/',
disallow: '/private/',
},
sitemap: 'https://acme.com/sitemap.xml',
};
}この関数は、次のような robots.txt ファイルを出力します:
User-Agent: *
Allow: /
Disallow: /private/
Sitemap: https://acme.com/sitemap.xmlRobots オブジェクトは、userAgent、allow、disallow、crawlDelay のルールと、sitemap、host のオプションを持つことができます。
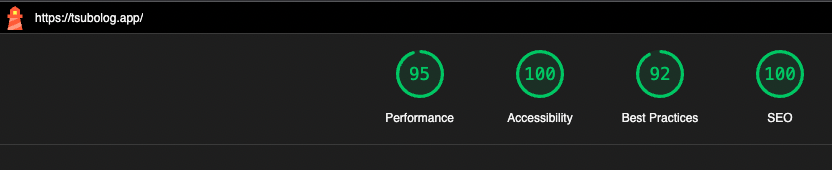
Lighthouse スコア
最後に Lighthouse スコアを確認してみましょう。 Lighthouse は、Google が提供するパフォーマンス測定ツールです。 導入方法は、Lighthouseを参照してください。
metadata や robots.txt を追加したことで、SEO のスコアが向上していることが確認できます。
参考
